Performance experiments with Geo::ReadGRIB and DBM
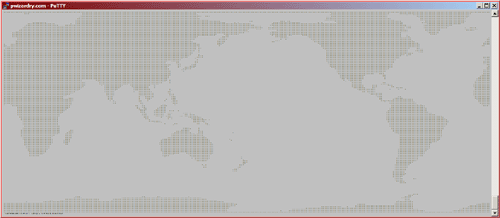 /This is a screen shot of my ssh session (set to 2-point type) printing data extracted using/
/Geo::ReadGRIB from a worldwide data set in a GRIB file. Since it's marine data, locations over/
/land are UNDEF and I print '*'. For anything else I print a space. This code was originally/
/developed to test my data extraction methods. Common errors like one-off would give a/
/distorted map. I adapted this code for my performance tests./
/This is a screen shot of my ssh session (set to 2-point type) printing data extracted using/
/Geo::ReadGRIB from a worldwide data set in a GRIB file. Since it's marine data, locations over/
/land are UNDEF and I print '*'. For anything else I print a space. This code was originally/
/developed to test my data extraction methods. Common errors like one-off would give a/
/distorted map. I adapted this code for my performance tests./
*next steps...*
Now that [Geo::ReadGrib http://search.cpan.org/~frankcox/Geo-ReadGRIB-0.4/lib/Geo/ReadGRIB.pm] has jumped the first hurdle and joined the world of public Perl modules there's more work to do. One of the first things I want to do is address some performance issues with certain use cases.
*Batch mode, Surf Break mode, and Random Access mode*
Geo::ReadGRIB was originally designed to work in batch mode and in what I will call "surf break mode". In batch mode it would be run as an automated process to create charts and graphs once or twice a day. In this case it didn't matter much if it took one minute or twenty minutes to run. One minute would be better, but longer wouldn't be much of a problem. In the second use case, users would be offered a selected number of locations, like popular surf breaks. The module supports this by caching extracted data in memory. Random Access mode could be quite slow and is the object of some work I'm doing now.
In the ReadGRIB module, data in a GRIB file is accessed using the extract() method, which expects data-type, latitude, longitude, and time as arguments for each extraction. If the data is already in the object's data structure it will return that. If not, the C program wgrib is called, which creates a temp file with a binary collection of data, including the requested one. That file is then opened, and Perl code vectors into the section of data requested. Batch mode on a fresh object would require a call to external code, and a file access for each data item, and would therefore be the slowest method. The same access on an object that has already accessed all the data using extract() should be much faster. Since extract() does checks of the requested parameters, and sets errors on out-of-range values, it should be faster still to pull data directly from the object data structure. This option works if you know all the data you want is already in the object.
*DBM experiments*
I've recently been exploring the DBM functions as a method of persistent storage and performance enhancement. The option I'm testing here is storing extracted GRIB data in a DBM database file and opening that. This data will persist after the Geo::ReadGRIB object closes.
*What's Faster and How Much Faster?*
I wrote a simple test that extracts about 1000 data items from a world wide data set and displays them on the screen. The /*Benchmark*/ module was used to keep times and report results. Here's what I got:
gExtract() no hits: 0.36/s (n=1)
gExtract() all hits: 9.14/s (n=1)
gPrintObject(): 21.33/s (n=1)
gPrintDBM(): 12.82/s (n=1)
As expected, extraction with a fresh object is quite slow, using over 3 seconds of CPU time (.36 per second). Running extract() again for the same data is about 30 times faster. Printing the data directly from the object data structure was more then twice as fast again. Printing the same data from an DBM file placed a respectable second place and might be a viable option to maintaining a long lived object.
cool.
.
[/items/Perl]
permanent link