|
|
About
Devlog :: And Wizardry, An ongoing attempt to amuse and challenge myself. Interested?
My Name
Frank L. Cox
Flavours
index
circa 1993
RSS
Links
Devlog
Surfers Weather
Pwizardry.com
raelity bytes ;-)

|
|
|
Thu, 03 Nov 2011
Vim just turned 20 and I just learned a new vim trick
It was 20 years ago, November second 1991. George H. W. Bush was president, the Soviet Union was dissolving, the World Wide Web barely existed, and the vim text editor was first released publicly, originally for the Amiga, on Fred Fish floppy disk #591. Twenty years is a hell of a long time in computer years but Vim is still going strong.
During the celebrations today (ongoing, although it's now after midnight) I stumbled on the Vim session feature. It lets you save the state of a editing session with all the open files, tabs, layout, and history. You can pick up where you left off with just one command. I've been living without this since Vim 7 came out with tab pages (in 2006). I got by mostly because I worked on always-on workstations or hibernate and restore laptops. I tend to keep editing sessions open through a whole project. It was always a hassle to shut down and start up again, but no more!
It's basicly simple. In Vim you can check out ":help session".
To save a session use ":mks[ession] name-of-session-file".
To open the session again in your shell type "vim -S name-of-session-file".
I created an alias in my cygwin .bashrc to open my current project session and mapped F2 in my .vimrc to the command to save the current session.
Not only that, but today I also discovered the fabulous new mintty terminal for cygwin. It's been a double awesome day.
Happy Vim day!
#
Sat, 02 Jul 2011
Windows 7 Essential Programs (says me), 2011 Edition
This is an update of my post from February 2010.
It's a list I made of programs I need to install on a new OS before I consider it ready to use. Most of these are essential to me either for work or play.
Next week I'm upgrading my main workstation to an unlocked i5, a SSD, and a motherboard which includes USB3 and room for a lot more RAM.
The programs are in the order I thought of them which is often also the order of importance.
MS Security Essentials (was AGV Free in 2009)
Chrome and FireFox (was just FF last time)
Git command line version (was Subversion but I won't install that until I need it)
Putty
PuttyCM (and unclick "Hide when minimized")
cygwin
Perl (Strawberry these days)
vmware player
Thunderbird and Clowdmark anti-spam
vim and plugins
Radiator
Audacity
Sync Toy
eWallet
winSCP
Retrospect
Beyond Compare
(last time I installed X Mouse but I just use the registry hack now)
easyBCD
New to the list:
Dropbox
Maya
Open Office
winDirStat (new to the list but old to the toolbox. Just put it on there, you'll need it some day)
Synergy 32bit (64bit version doesn't work for me)
Input Director (If both systems are PC this is great, and you can cut and paste files, but I need Synergy for cross platform)
EAC (hey look, there's a new version after all these years. Hope it's good...)
FLAC
I'll probably wait for the 1.7 Ti SDK to install Titanium Developer and the Android SDK tools. I'll stay on the iMac for now.
Set Win7 for X mouse and "better" power settings i.e. don't shut down after some idle time...
That' about it. #
Sun, 06 Mar 2011
Setting up a TurnKey Linux core VM for Nodejs (the way I like it)
There's a lot to like about TurnKey Linux packages. They're a damn easy way to set up a dev application server. I've used the Rails and PostgreSQL versions already for projects and there are over 45 version to chose from.
[http://www.turnkeylinux.org/]
This time I want to test an idea with Nodejs which means I have to roll my own. I grabbed the "core" version and went from there.
I needed to add build tools and, I don't like to to do everything as root so I added a user with sudo powers...
Add a user account for yourself and then, as root...
apt-get update
apt-get install build-essential
apt-get install sudo
vi /etc/sudoers
you know the drill, add the user...
Then, as a user, grab the latest nodejs package:
git clone https://github.com/joyent/node.git
if you want the bleeding edge, or download a stable version from github. Than...
./configure
make
sudo make install
make test
Have fun.
#
Mon, 29 Mar 2010
Moving Subversion repositories to Git
Mostly FMI (for my information)...
I've been wanting to check out git for a while and the time was right. I'll be moving one of my server accounts soon. That includes some Subversion repositories. It's not too hard to move svn to a new server but it turned out to be even easer to port it all to git.
Here's what I did:
[There are lots of ways to do this, but this worked for me...]
> /git svn clone svn+ssh:!/!/user@pwizardry.com!/rest-of-svn-style-url/
This creates a new git repository in the current directory with the same name and all the contents of the Subversion repository, including all the revision history. A lot of stuff scrolls by listing every commit and every file involved.
It died for me part way through with this encouraging message: *error: git-svn died of signal 13* which is from an unresolved bug. If you cd to the new repository and type
> /git svn fetch/
it will continue where it left of.
What I had when this was done was a git working copy. This includes all the diffs and objects that make a repository, plus a copy of the current versions of all files and directories. What I wanted was a "bare" repository on my server that doesn't have all the files. I'll use this to clone new working copies of my code where I will be working on it and then pushing changes back.
For example, on my laptop:
> /git clone ssh:!/!/munging.us!/xxx!/local!/git!/cell/
/[hack, hack]/
> /git commit -a -m "I hacked and hacked"/
> /git push ssh:!/!/munging.us!/xxx!/local!/git!/cell/ or just /git push origin/
Getting back to making a bare repostiry... It would be nice if /git svn/ took a --bare option, but it doesn't. The trick is to clone a new bare copy with a different name and blow away the original. Then rename the clone with the original name.
> /git clone --bare cell cell.temp/
> /rm -rf cell/
> /mv cell.temp cell/
With all the warts showing in the first few git commands I typed, I had to wonder if it was ready for prime time! To be fair this was all in the git-svn command which, in the end, did an impressive job for me. One command and some cleanup (and a bunch web searching) did the trick. Bringing over the rest of my svn repositories was easy.
git!
#
Thu, 04 Feb 2010
Windows 7 Essential Programs (says me)
This is a list I made of programs I need to install on a new OS before I consider it ready to use. Most of these are essential to me either for work or play.
I made this list when I installed Win7 RC and now I'll need to do this again for the release version. They are in the order I thought of them which is often also the order of importance.
MS Security Essentials (was AGV Free)
FireFox
Subversion
Tortoise SVN
Putty
PuttyCM (and unclick "Hide when minimized")
cygwin
Perl (Strawberry these days)
Squeezecenter
vmware player
Thunderbird and Clowdmark anti-virus
vim (my version with plugins I will check out from svn)
Radiator
Audacity
Sync Toy
eWallet
winSCP
Retrospect
Beyond Compare
X Mouse
easyBCD
Set Win7 for X mouse and "better" power settings i.e. don't shut down after some idle time...
That' about it. #
Thu, 01 Oct 2009
Speaking of Perl modules that work -> Net::PubSubHubbub::Publisher
The other day I mentioned that I was looking at [PubSubHubbub http://code.google.com/p/pubsubhubbub/] (PuSH). I was inspired by this post on [Rogers Cadenhead's workbench http://workbench.cadenhead.org/news/3560/pubsubhubbub-lot-easier-than-sounds]. Rogers lays PuSH publishing out in a few steps. Basically, add some XML to your RSS feed and ping a hub when you publish.
I made the needed changes to my blosxom 2.1.1 cgi code, down near the end:
/rss head <?xml version="1.0" encoding="$blog_encoding"?>/
*/rss head <rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">/*
/rss head <channel>/
/rss head <title>$blog_title</title>/
*/rss head <atom:link href="http://pwizardry.com/devlog/index.cgi/index.rss" rel="self" type="application/rss+xml" />/*
*/rss head <atom:link rel="hub" href="http://pubsubhubbub.appspot.com" />/*
(*Bold* lines are the inserted changes.)
Then I installed the Perl module [Net::PubSubHubbub::Publisher http://search.cpan.org/~bradfitz/Net-PubSubHubbub-Publisher-0.91/] and hacked together this quick program:
/#! /usr/bin/perl/
/use Net::PubSubHubbub::Publisher;/
/use strict;/
/use warnings;/
/my $hub = "http://pubsubhubbub.appspot.com";/
/my $topic_url = "http://pwizardry.com/devlog/index.cgi/index.rss";/
/my $pub = Net::PubSubHubbub::Publisher->new( hub => $hub);/
/$pub->publish_update( $topic_url ) or die "Ping failed: " . $pub->last_response->status_line;/
/print $pub->last_response->status_line, "\n"; # I want to see it even if it didn't fail/
I then went to FeedBurner and added my feed and subscribed to it in Google Reader.
I was about to say "Updates show up in Google Reader in seconds" except this one didn't. I'm not sure why but I did find this post [...Get with it, PuSH, http://www.educer.org/2009/09/29/on-pubsubhubbub-part-2-get-with-it-push-youre-supposed-to-be-realtime/]
hmmm...
#
local::lib for local Perl module installs -- it made my day
I recently moved this site to a new ISP and had to install some Perl modules that aren't provided on the server. In my case I also needed to install [Catalyst http://www.catalystframework.org/] which includes dozens of modules and a ton of dependencies.
This is a common task for any Perl programmer who doesn't have root or who just wants to install some modules outside the global locations. It's also a common Perl headache.
There are plenty of sites on the web that try to tell you how to do this but hardly any mention [local::lib http://search.cpan.org/~apeiron/local-lib/] yet. local::lib has been around a couple of years now and I'm glad I found it.
I just followed the instructions for the bootstrapping technique.
Download and unpack the local::lib tarball from CPAN as usual and then:
perl Makefile.PL --bootstrap
make test && make install
perl -I$HOME/perl5/lib/perl5 -Mlocal::lib >> ~/.cshrc
Works great!
#
Tue, 22 Sep 2009
I'm looking at PubSubHubbub today.
I've seen some buzz about the "real-time web" lately and then I saw this post [http://workbench.cadenhead.org/] #
Mon, 21 Sep 2009
just a test, nothing to see here...
#
Sun, 20 Sep 2009
I just updated this site to Blosxom 2.1.2
This isn't a big deal but the feed support is cleaner and I have a project in mind.
#
Tue, 07 Apr 2009
Flash Player Policy File.
To support my experiments in Flex development I've added a crossdomain.xml file to the pwizardry.com web server. This file sets policies and meta-policies that allow access to files on the server. Without it no access is allowed at all from browser based Flash player. It also satisfies the requirements for a meta-policy which otherwise generates a warning in the debug version of the player which I am using.
It looks like this:
<cross-domain-policy>
<allow-access-from domain="*"/>
<site-control permitted-cross-domain-policies="master-only"/>
</cross-domain-policy>
For more see [http://www.adobe.com/go/strict_policy_files] #
Thu, 26 Mar 2009
What's happening with me?
Last week I released a major update to my Perl module Geo::ReadGRIB on the CPAN (the official source of Perl extensions and the main reason you get so many hits when you Google Frank Lyon Cox).
I've just started on a long simmering project to replace the Java applet on my website (which I wrote in 2000: [http://www.pwizardry.com/buoyBrowser/] ), with something more modern. Flash or Flex is what I'm thinking. I also want to make some interactive animated weather forecast maps from GRIB data as a demo of my module. This means learning Actionscript which used to make me hold my nose, but they are up to version3 now and it looks, and smells, a lot better.
My wife is a very successful illustrator and is making some art for a game project which is using flash. Coincidently, they are looking for an expert Actionscript programmer. It's possible I'll be able to contribute something to that project if I get my butt in gear. I any case, this points to possible future family business ideas.
I've also been involved in some major home improvement projects. It's been fun! I am looking for a job though.
#
Wed, 05 Nov 2008
Workstation Woes
My home built desktop workstation started acting up a few months ago. It started spontaneously restarting once every week or so. Over time it happened more and more often and it became unusable. It turned out to be bad RAM but it took a long time to get to a diagnosis.
For one thing, it passed an overnight RAM test way back when I first noticed the problem. At that time it had only crashed a few times with a week or more between. I've never had RAM go bad before so while the problem got worse I was looking elsewhere.
After I finally solved the RAM problem I started having boot problems. I would hear the single beep that says everything is OK so far, and then I would see the monitor come out of power save mode but there would be no splash screen from the BIOS. It would just hang there forever. If I tried again latter it might start normally and then work fine until I shut down again. This went on for a few days.
It turns out I'd been using my laptop as a stand in workstation with the same monitor and wireless mouse. I'd swap the USB receiver for the mouse back an forth to my main box when it was working. I also had a wired USB mouse on my workstation that I put on there while testing. It turns out the workstation will not boot with both mouses attached even though it works fine with both after it's up. (!) One or the other is OK for booting but not both. (And I'd move the wireless to back to the laptop when I gave up trying to boot my main system...)
Dang! I hope the hacking gods have less tedious projects in mind for me now. Please please please!
#
Tue, 21 Oct 2008
Installing the Zorba XQuery Processor
I stayed up late last night before last doing a [Zorba http://www.zorba-xquery.com/] 0.9.21 build and install. I was up late again last night putting on the 0.9.4 version.
Zorba is an open source XQuery processor written in C++. There's a short list of dependencies and the install process is is the familiar sequences starting with ./configure or cmake or read the docs a little more... and then repeat.
The only snag I tripped over was when I grabbed the latest 3.0 Xerces-C++ and Zorba wanted 2.x (grater then 2.7.0). I'm also still looking for the Python bindings, not to mention any future Perl ones.
#
Tue, 17 Apr 2007
VIM Block Indents - just so I remember...
*In gvim, to bring a block to standard indent level:*
Select one of the block boundaries (like { or } For one) and input *=%*
One potential problem with this is that this will remove any "non-standard" indenting you might have. On the plus side, it will remove non-standard indenting.
*To indent a block one more level:*
Select a block boundary and enter *>%*
This moves everything over one level, including the non-standard bits.
To move every thing in the block except the boundaries, use *>i{*
#
Fri, 02 Mar 2007
more Cygwin/X trivia...
To automate the "xhost +SERVER_IP" step edit /etc/X0.hosts and include the IP addresses of the servers that can use the X server. For example:
$ echo "10.0.0.1" >>/etc/X0.hosts
For startup, I made a copy of bash.bat called x.bat and changed the last line to:
bash -c startx
These two changes reduced starting the X server to an icon click. It does spawn two windows though that need to stay running. This is an improvement though.
#
Fri, 22 Dec 2006
Bug fix for Ubuntu login screen symptom
On day my Ubuntu login screen changed to to the ugly one with the daisy on it. Also the shutdown screen didn't have the shutdown option in it anymore. I had to choose logout, which led to the ugly login screen, which did have the logout choice under Options. I tried to fix it right off using gdmsetup but it wouldn't start.
Follow that?
A web search led to a number of reports of the same problem with no solution. Then I found this:
[https://launchpad.net/distros/ubuntu/+source/gdm/+bug/66034]
The fix is to move /etc/rc2.d/S13gdm to S21gdm ...
works.
#
Thu, 21 Dec 2006
Just for my information... Running Cygwin/X
To start a X server on cygwin and, have it work for me, I did:
> startx &
Welcome to the XWin X Server
Vendor: The Cygwin/X Project
Release: 6.8.99.901-4
[...lots more...]
> xhost +
xhost: unable to open display ""
> xhost +10.128.1.131
xhost: unable to open display ""
> export DISPLAY=127.0.0.1:0.0
> xhost +SERVER-IP-ADDRESS
SERVER-IP-ADDRESS being added to access control list
Then
ssh user@SERVER-IP-ADDRESS
export DISPLAY=CIGWIN-SYSTEM_IP
rock and roll...
Probably the setting of the display to the local host IP on Cygwin could/should be set in a config file somewhere...
#
Wed, 18 Oct 2006
Good article on automation of Perl module deployment:
[From IBM developer works http://www-128.ibm.com/developerworks/library/l-depperl.html?ca=drs-l1105]
It used a combination of the CPAN module and some scripts
#
Sat, 15 Jul 2006
Africa centric swell animation using Geo::ReadGRIB
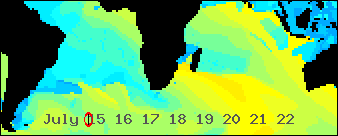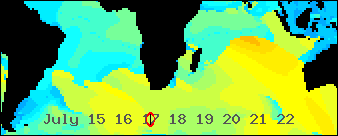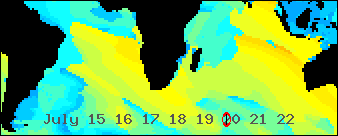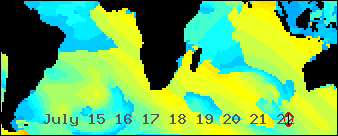 /An animated GIF abstracted from a world wide Wavewatch III GRIB dataset/
/showing all the seas were swells bound for southern Africa might be generated/
/An animated GIF abstracted from a world wide Wavewatch III GRIB dataset/
/showing all the seas were swells bound for southern Africa might be generated/
*A work in progress*
The above animated image shows the period of the primary wave for seven days starting today, Greenwich time. It's still a work in progress. I spent most of the day implementing a number of ideas that have been germinating in my head for a while. I'm feeling good about what I have so far.
*Problem 1. Put Africa in the center*
The zeroth line of longitude runs through Africa. This puts the south Atlantic and south Indian oceans, which I want to include, on opposite ends of the world map. This is a challenge for the generalized map image drawing software I'm working on. I want to feed it a */Geo::ReadGRIB/* data structure and get a map animated by time. It, naturally, wants to put lower numbered longitudes to the west of higher numbered ones. A ReadGRIB object is hash based so I need to sort my data by time and then by longitude and then latitude. The elegant solution would be to reimplement my sort so it knows that the world is round. For now, I use a cheep trick instead. I shift all longs west until they are in order again.
*Problem 2. Come up with a time display you can /SEE/ while watching the data flow*
I'm using an analog solution. Most animations from Wavewatch III data that I've seen use a digital display. One typical solution shows the date of the GRIB file and a changing "forecast hour". This is a number that changes to show the how many hours the current frame is after the "nowcast" time. It's not very easy to see what day a swell is predicted to hit your beach. You have to see a number in the corner of your eye and do some math in your head. It's much easier to interpret a pointer moving along an analog scale. It's harder to program of course.
*Make the image about 350 pixels wide*
The only Wavewatch III data file I know of that shows the Indian Ocean is the worldwide nww3 series. They have a resolution of 1.25 degrees of longitude. I want an image about 350 pixels wide and I decided I might as well show a wider view then originally planed. It's 210 degrees wide -- 168 data points. Then I exactly double the size using a resample function.
*What's left to do?*
- Cover jaggy edged landmass shadow areas with /hopefully/ smother map images.
- Create a key image that will map the colors used to data values. This will probably be a colorful ban along the top or bottom
- Tweak the data-to-color mappings to best show potentially surfable swells. This will be tricky...
#
Fri, 23 Jun 2006
Animated data visualization application using Geo::ReadGRIB
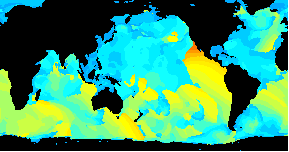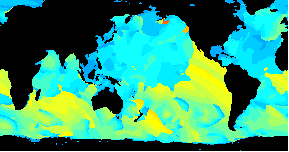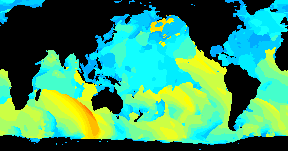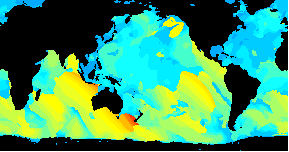 /An animated GIF of a world wide Wavewatch III GRIB dataset/
/An animated GIF of a world wide Wavewatch III GRIB dataset/
*GRIB to GIF*
The above image shows the period of the primary wave for seven days starting this last Tuesday, June 20th. The red end of the color spectrum is used for longer period. There's some nice storm activity in the South Indian Ocean. At the beginning we see a pulse passing New Zealand and then, over the week, a bigger one develops and smacks South Australia and NZ. A small amount of that may make it to our shores.
*Geo::ReadGRIB for Fun and Profit*
I've been working on project for a major surf magazine. I'll develop an application that will draw animated GIF's each day from Wavewatch III forecast data. This is the first application I've done using Geo::ReadGRIB since it went public.
I won't say much more about my project or the client for now. In the future I may publish example code or a module that will use Geo::ReadGRIB and draw simple images of Wavewatch III data like the one above. #
Performance boost in Geo::ReadGRIB .05
*New method extractLaLo()*
I posted [Geo::ReadGRIB http://search.cpan.org/~frankcox/Geo-ReadGRIB-0.5/lib/Geo/ReadGRIB.pm] version .05 which includes a new method with the signature:
*/extractLaLo(data_type, lat1, long1, lat2, long2, time)/*
This will extract all data for a given /data_type/ and /time/ in the rectangular area defined by (lat1, long1) and (lat2, long2) where lat1 >= lat2 and long1 <= long2. That is, lat1 is north or lat2 and long1 is west of long2. This new method takes advantage of the fact that it takes only one call to wgrib to extract all the locations in the GRIB file for a given type and time.
The original extract() method was designed for extracting GRIB data for a single location. I'm working on a project now that will create animated surf whether charts for a large area of ocean. Getting the data is much faster using Geo::ReadGRIB .05.
*How much faster?*
I posted some informal benchmarks [earlier http://pwizardry.com/devlog/index.cgi/2006/06/04#DBM.and.ReadGRIB] . Here are some results using a similar test using a different data set and a larger number of points.
extract() no hits: 0.14/s 2.44s/
extractLaLo() no hits: 4.74/s .21s/
This just runs an extract for about 22000 data points using each method. The "no hits" means the objects were fresh and all data had to come from the GRIB file. (Recall, ReadGRIB will cache data in memory and only go to the file if it needs to.) It took the version using extract() about 2.4 seconds per run while extractLaLo() took just .21. That's over 11 times faster. Of course poor extract() was designed for single point at a time extraction but everyone loves a winner.
For me, it means the difference between a starch and a coffee break while running tests that need a lot of new GRIB data.
#
Sun, 04 Jun 2006
Performance experiments with Geo::ReadGRIB and DBM
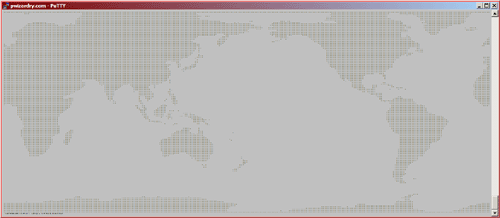 /This is a screen shot of my ssh session (set to 2-point type) printing data extracted using/
/Geo::ReadGRIB from a worldwide data set in a GRIB file. Since it's marine data, locations over/
/land are UNDEF and I print '*'. For anything else I print a space. This code was originally/
/developed to test my data extraction methods. Common errors like one-off would give a/
/distorted map. I adapted this code for my performance tests./
/This is a screen shot of my ssh session (set to 2-point type) printing data extracted using/
/Geo::ReadGRIB from a worldwide data set in a GRIB file. Since it's marine data, locations over/
/land are UNDEF and I print '*'. For anything else I print a space. This code was originally/
/developed to test my data extraction methods. Common errors like one-off would give a/
/distorted map. I adapted this code for my performance tests./
*next steps...*
Now that [Geo::ReadGrib http://search.cpan.org/~frankcox/Geo-ReadGRIB-0.4/lib/Geo/ReadGRIB.pm] has jumped the first hurdle and joined the world of public Perl modules there's more work to do. One of the first things I want to do is address some performance issues with certain use cases.
*Batch mode, Surf Break mode, and Random Access mode*
Geo::ReadGRIB was originally designed to work in batch mode and in what I will call "surf break mode". In batch mode it would be run as an automated process to create charts and graphs once or twice a day. In this case it didn't matter much if it took one minute or twenty minutes to run. One minute would be better, but longer wouldn't be much of a problem. In the second use case, users would be offered a selected number of locations, like popular surf breaks. The module supports this by caching extracted data in memory. Random Access mode could be quite slow and is the object of some work I'm doing now.
In the ReadGRIB module, data in a GRIB file is accessed using the extract() method, which expects data-type, latitude, longitude, and time as arguments for each extraction. If the data is already in the object's data structure it will return that. If not, the C program wgrib is called, which creates a temp file with a binary collection of data, including the requested one. That file is then opened, and Perl code vectors into the section of data requested. Batch mode on a fresh object would require a call to external code, and a file access for each data item, and would therefore be the slowest method. The same access on an object that has already accessed all the data using extract() should be much faster. Since extract() does checks of the requested parameters, and sets errors on out-of-range values, it should be faster still to pull data directly from the object data structure. This option works if you know all the data you want is already in the object.
*DBM experiments*
I've recently been exploring the DBM functions as a method of persistent storage and performance enhancement. The option I'm testing here is storing extracted GRIB data in a DBM database file and opening that. This data will persist after the Geo::ReadGRIB object closes.
*What's Faster and How Much Faster?*
I wrote a simple test that extracts about 1000 data items from a world wide data set and displays them on the screen. The /*Benchmark*/ module was used to keep times and report results. Here's what I got:
gExtract() no hits: 0.36/s (n=1)
gExtract() all hits: 9.14/s (n=1)
gPrintObject(): 21.33/s (n=1)
gPrintDBM(): 12.82/s (n=1)
As expected, extraction with a fresh object is quite slow, using over 3 seconds of CPU time (.36 per second). Running extract() again for the same data is about 30 times faster. Printing the data directly from the object data structure was more then twice as fast again. Printing the same data from an DBM file placed a respectable second place and might be a viable option to maintaining a long lived object.
cool.
. #
Mon, 15 May 2006
Geo::ReadGRIB now on CPAN!!!!
At last.
I've finally solved the technical issues in building my ReadGRIB module, written
the documentation and done some multi platform tests...
[Geo::ReadGRIB http://search.cpan.org/~frankcox/Geo-ReadGRIB-0.4/lib/Geo/ReadGRIB.pm] is now up on [CPAN http://cpan.org] #
Mon, 24 Apr 2006
Subversion for Perl module development on Geo-ReadGRIB
I'd been doing my development on Geo-ReadGRIB without using source control. The main reason was that, in the MakeMaker environment the .svn/ directories is problematic. The big problem is that the generated makefile will try to do something reasonable with the .svn/ stuff as a part of the distribution. Reasonable in this case means not ignoring them.
I should have realized that I wasn't the first one to have this problem. A few minutes searching turned up a solution at [use.perl.org http://use.perl.org/~rafael/journal/9262]. Basically, I need to create a MANIFEST.SKIP file and add my own version of libscan() to Makefile.PL ...
Works like a charm. #
Sun, 23 Apr 2006
Not /exactly/ top_targets... But I was getting close
Really, it seems best not to mess with top_targets at all. I started looking for an empty section that, ideally, was a target anyway. /*dynamic*/ fit the bill. In fact, I had to stub it out with a comment to keep the make from erroring out with /"don't know how to make dynamic"/...
I think it's running dynamic because it found wgrib.c -- even though I had dynamic in the SKIP section.
Anyway, this works and the dist builds right on Linux FreeBSD and windows. This means I can stop messing with the make part and finish the distro for release.
sub MY::dynamic {
'
dynamic :: $(INST_ARCHAUTODIR)/wgrib.exe
@$(NOOP)
$(INST_ARCHAUTODIR)/wgrib.exe: $(C_FILES)
--tab-- $(CC) -o wgrib.exe wgrib.c
--tab-- $(MKPATH) $(INST_ARCHAUTODIR)
--tab-- $(CP) wgrib.exe $(INST_ARCHAUTODIR)
';
}
#
Sat, 01 Apr 2006
top_targets ... Now I'm starting to get it.
I've been letting the Geo::ReadGRIB project simmer along for a while now. I've worked on a few other projects in the mean time. I even started and finished one, Games::Suduku.
The main thing I needed to do is find out enough about ExtUtils::MakeMaker and the make files it creates. This means digging into /make/ again too. Recall that I want to compile a third party C program which my module code wall then use. I can't find any examples doing this anywhere so I had to discover a good way myself.
Looks like the top_targets section is the place to do the compile:
(In lib-wgrib/)
sub MY::top_targets {
'
all :: static
pure_all :: static
static :: wgrib$(LIB_EXT)
wgrib$(LIB_EXT): $(C_FILES)
--tab-- $(CC) -o wgrib wgrib.c
--tab-- $(MKPATH) $(INST_ARCHAUTODIR)
--tab-- $(CP) wgrib $(INST_ARCHAUTODIR)/wgrib
';
}
#
.c$(OBJ_EXT):
$(CCCMD) $(CCCDLFLAGS) -I$(PERL_INC) $(DEFINE) $*.c
# --- MakeMaker const_cccmd section:
CCCMD = $(CC) -c $(INC) $(CCFLAGS) $(OPTIMIZE) \
$(PERLTYPE) $(MPOLLUTE) $(DEFINE_VERSION) \
$(XS_DEFINE_VERSION)
CC: cc -c
INC:
CCFLAGS: -fno-strict-aliasing -I/usr/local/include
OPTIMIZE: -O
PERLTYPE:
DEFINE_VERSION: -VERSION=\"0.10\"
XS_DEFINE_VERSION: -DXS_VERSION=\"0.10\"
-DPIC -fpic -/usr/local/lib/perl5/5.6.1/i386-freebsd/CORE wgrib.c #
Mon, 13 Mar 2006
Not perfect but my lib is coming along...
My proposed name is Geo::ReadGRIB. I've been struggling with the makefiles for a while and I've kludged my way to a truce.
Makes without error but compiles wgrib.c twice...
It's good enough now to work on other parts of the project.
*./Makefile.PL:*
use 5.006;
use ExtUtils::MakeMaker;
# See lib/ExtUtils/MakeMaker.pm for details of how to influence
# the contents of the Makefile that is written.
WriteMakefile(
NAME => 'Geo::ReadGRIB',
VERSION_FROM => 'lib/Geo/ReadGRIB.pm', # finds $VERSION
AUTHOR => 'NULL <lyon@vwh.net>',
SKIP => 'qw[static static_lib dynamic dynamic_lib]',
MYEXTLIB => 'lib-wgriblib$(LIB_EXT)/',
);
sub MY::dynamic_lib {
'
ARMAYBE = :
OTHERLDFLAGS =
INST_DYNAMIC_DEP =
$(INST_DYNAMIC): $(OBJECT) $(MYEXTLIB) $(BOOTSTRAP) $(INST_ARCHAUTODIR)/.exists $(EXPORT_LIST)
$(PERL_ARCHIVE) $(PERL_ARCHIVE_AFTER) $(INST_DYNAMIC_DEP)
@echo "Make:MY::dynamic_lib not needed -- don\'t worry"
';
}
sub MY::static {
'
static :: Makefile $(INST_STATIC)
@echo "MY::static: not needed here -- go home"
';
}
sub MY::postamble {
'
$(MYEXTLIB) : lib-wgrib/Makefile
cd lib-wgrib && $(MAKE) $(PASSTHRU)
';
}
*lib-wgrib/Makefile.PL:*
use 5.006;
use ExtUtils::MakeMaker;
WriteMakefile(
NAME => 'Geo::ReadGRIB::lib-wgrib',
SKIP => 'qw[all static static_lib dynamic dynamic_lib]',
clean => {'FILES' => 'liblib-wgrib$(LIB_EXT) wgrib'},
);
sub MY::const_cccmd {
'
CCCMD = $(CC) -o wgrib
';
}
sub MY::dynamic_lib {
'
ARMAYBE = :
OTHERLDFLAGS =
INST_DYNAMIC_DEP =
$(INST_DYNAMIC): $(OBJECT) $(MYEXTLIB) $(BOOTSTRAP) $(INST_ARCHAUTODIR)/.exists $(
EXPORT_LIST) $(PERL_ARCHIVE) $(PERL_ARCHIVE_AFTER) $(INST_DYNAMIC_DEP)
@$(NOOP)
@echo "lib-wgrib/Make:MY::dynamic_lib not needed -- don\'t worry about thi
s either"
';
}
sub MY::dynamic_bs {
'
BOOTSTRAP = "*.bs"
$(BOOTSTRAP):
@echo "MY::dynamic_bs - bs, good name"
$(INST_BOOT):
@echo "MY::dynamic_bs - more of the same..."
';
} #
It's hard to come back from Mexico
A week in tropical Mexico can do a full reset on your systems.
now... what was it I doing before? #
Fri, 24 Feb 2006
More ReadGRIB: Makefile.PL hacking
I want to distribute a third party C program called wgrib.c with my module. The C code needs to be compiled on the target platform when the module is installed on the target platform. Then my Perl code will need to be able to use it.
*this isn't done yet but so far...*
I found some good hints from /perlXStut/
# First I added a directory named lib-wgrib/ and moved the C source there.
# Then I added this to the generated Makefile.PL:
WriteMakefile(
[...]
MYEXTLIB => 'lib-wgriblib$(LIB_EXT)/',
);
sub MY::postamble {
'
$(MYEXTLIB) : lib-wgrib/Makefile
cd lib-wgrib && $ (MAKE) $ (PASSTHRU)
';
}
# in lib-wgrib/ I created another Makefile.PL:
use 5.006;
use ExtUtils::MakeMaker;
WriteMakefile(
NAME => 'Geo::ReadGRIB::lib-wgrib',
SKIP => 'qw[all static static_lib dynamic dynamic_lib]',
clean => {'Files' => 'liblib-wgrib$(LIB_EXT)'},
);
sub MY::const_cccmd {
'
CCCMD = $(CC) and other stuf TBD...
';
}
The trick here is that the MY:: subroutines override the standard libs that write sections of the Makefile created. You can see the names of these subs in the comments in the Makefile.
Still working... #
Thu, 16 Feb 2006
Work on my first CPAN contribution: ReadGRIB
For my first CPAN module I'm planing to offer ReadGRIB, a lib that will open NECP GRIB file. That's National Centers for Environmental Prediction GRIdded Binary files. They're used for scientific data. In this case, my module was crated to read marine whether prediction data.
More on my project later. I'll say for now that it includes a perl .pm file which wraps a compiled C program called wgrib. I don't yet know how to package a perl module the includes C code used this way. That is, I will want to have the C code compiled to a stand alone program at module install time and then the perl .pm code will be able to use it.
...
Just to remind myself:
% /usr/local/bin/perl5.8.4 -I/usr/home/lyon/local/lib/site_perl /usr/local/bin/h2xs ...
To run /h2xs/ with libs from my own include locations. #
Tue, 07 Feb 2006
Powerful swell smashes my web site
They held the Mavericks surf contest today because of the powerful conditions. The swell made my buoyBrowser application stop working. It even hung one of my versions of Firefox.
Hear's the error that was triggered by these rare conditions:
/exception: java.lang.NumberFormatException: for input string "22+"/
My Java buoyBrowser application broke because an extremely long period swell was running yesterday. It turns out that the dominant period was over 22 seconds which is the longest period in the data files I download. The CDIP data files show this as "22+". It's rare to see even a foot of 22+ but it was up to 7 feet for that component.
I took a screen shot shown below. I have the pointer on a time when the 22+ band is 5.5 feet and is the largest component. There were about 10 data points where this was true that day. I have back end software in Perl that scrapes the CDIP data files and precalculates everything for the Java app on my page. For one thing, it determines which swell component has the most energy. In this case it was 22+ which isn't a number. This is used in the 'Average Wave" display where the size is calculated combination of the size of all the individual components and the period is the period of the strongest component. In the six years this application has be running this is the first time 22+ has been dominant.
Funny how many humbling lessons a fun little personal programming project can teach you.
The fix? I now make sure no non numeric data gets into my data files. (s/[^0-9\s]//g)
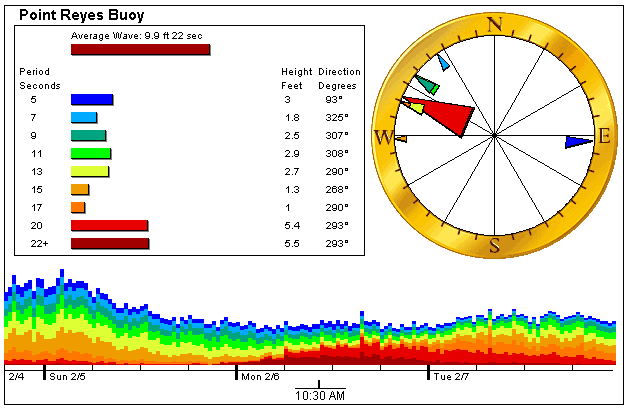
#
Mon, 06 Feb 2006
I just got an account on PAUSE, the Perl Authors Upload Server
I'll be able to contribute Perl code to CPAN.org now. My CPAN id is FRANKCOX and I'll be adding some of my surf forecast stuff soon.
Check out [PAUSE http://pause.perl.org] and [CPAN.org http://CPAN.org] for more info... #
I'm trying out Technorati today...
This is just a test.
...of my [Technorati Profile http://technorati.com/claim/suf8kcqr4]
You may return to your normal activities. #
Sat, 04 Feb 2006
I added a logo to my buoy data images
While watching the POE demo app tail my web log files I noticed a referrer to a [certain http://www.niceness.org/new_surf/archives/001116.html] surfer's web site popped up a lot.
What was happening is that there is an <img> tag posted on the page pointing to one of my buoy data gifs.
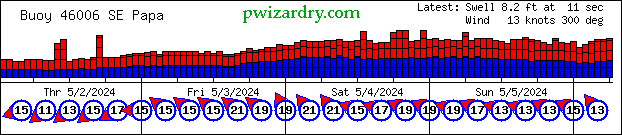 This image changes every hour so it makes a kind of sense to do it this way. The latest version will always display on his page. As an added bonus for the linker, it's my server that provides the resource.
Now Ethan is a really nice guy and I think it's great that the images are getting used by more local surfers. I did decide that I wanted to tag the images in some way though.
I added this text to all my buoy data images.:
This image changes every hour so it makes a kind of sense to do it this way. The latest version will always display on his page. As an added bonus for the linker, it's my server that provides the resource.
Now Ethan is a really nice guy and I think it's great that the images are getting used by more local surfers. I did decide that I wanted to tag the images in some way though.
I added this text to all my buoy data images.:
 It's pretty jaggy edged but that's because it has to be a GIF image. Anti aliasing would look strange too (especially on a non-white background like Ethan's site ;-).
I want to redo the images again to make this a little less prominent. I'm thinking of adding some extra space at the bottom for a line of text including a tag of some sort.
Coming soon...
It's pretty jaggy edged but that's because it has to be a GIF image. Anti aliasing would look strange too (especially on a non-white background like Ethan's site ;-).
I want to redo the images again to make this a little less prominent. I'm thinking of adding some extra space at the bottom for a line of text including a tag of some sort.
Coming soon...
#
Fri, 03 Feb 2006
Perl Play: put on POE today
I installed POE and its /many/ dependencies tonight in ~/local/lib/site_perl and tested with a demo application from [Watching log files http://www.stonehenge.com/merlyn/PerlJournal/col01.html]
The application /tails/ the web server access log and displays the results on a web page colorized by time. It's a way to spot clusters of hits. Really though it's an interesting demo more than anything.
I hangs and dies after a while with the error:
[= Error accept Too many open files (24) happened after Cleanup!]
Cool so far... #
Sat, 28 Jan 2006
Fix to coffeeFind Perl backend code
The new sort feature reveled an issue with the database data. Some of the fields have white space at the beginning. These were sorted to the top of the list. This is technically correct but not what I want to see.
I made a small change to the Perl code that scrapes the HTML coffee review files and puts the data into the database tables used by coffeeFind. Now I make sure there's no leading white space.
Fixed. #
Fri, 27 Jan 2006
Late Night Rails Hacking
I finally circled back around and started poking at my CoffeeFind /*Ruby on Rails*/ application again. I stayed up way late. I wanted to get the [sort-by-column http://pwizardry.com/devlog/index.cgi/2006/01/06#CoffeeFind_I_Want] feature working and I couldn't quit in the middle.
*Lessons learned:*
just a random list so I don't forget...
- You have to start WEBrick from inside the application directory, /seems that way anyway.../
- To pass params from view to controller. In the view I do this:
/<% link_to "![sort]", :action => "show_ordered_by", :id => by %>/
The param here is "by" which is set up above:
/<% by = column.name %>/
I needed to do this because no matter what I did with quotes I couldn't just put /column.name/ as the :id value. This bit of code is used in a loop to put a sort tag on each of the column head cells so I can signal the controller method to sort on that column.
On the controller I have:
/def show_ordered_by/
/@reviews = Reviews.find(:all, :order => @params['id'])/
/end/
The @params array has the /id/ value the link will pass.
I had added the /*show_ordered_by*/ method to be the target of the links that will resort the table. I needed a separate view .rhtml file to display it. This file turned out to be identical to the one for the /*sort*/ method that draws the table the first time you view the link. In accordance with the DRY principle I changed the /*sort*/ method to be:
/redirect_to :action => 'show_ordered_by', :id => 'id'/
And for good measure I added a /*index*/ method which is identical. This way you just need to use [http://pwizardry.com/review http://pwizardry.com/review]
All this is based on approximately zero knowledge of Ruby or Rails so it's probably wack. #
Sat, 14 Jan 2006
My new tableless, XHTML/CSS Devlog upgrade
I spent a lot of time this last week redesigning this devlog. #
|
|