
Animated data visualization application using Geo::ReadGRIB
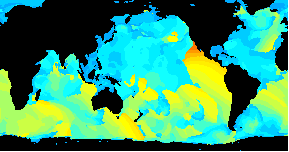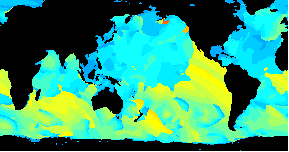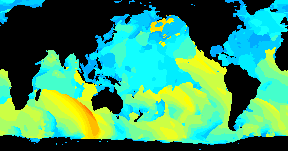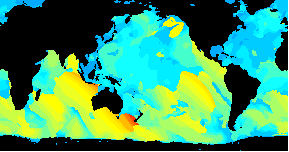 /An animated GIF of a world wide Wavewatch III GRIB dataset/
/An animated GIF of a world wide Wavewatch III GRIB dataset/
Performance boost in Geo::ReadGRIB .05
*New method extractLaLo()* I posted [Geo::ReadGRIB http://search.cpan.org/~frankcox/Geo-ReadGRIB-0.5/lib/Geo/ReadGRIB.pm] version .05 which includes a new method with the signature: */extractLaLo(data_type, lat1, long1, lat2, long2, time)/* This will extract all data for a given /data_type/ and /time/ in the rectangular area defined by (lat1, long1) and (lat2, long2) where lat1 >= lat2 and long1 <= long2. That is, lat1 is north or lat2 and long1 is west of long2. This new method takes advantage of the fact that it takes only one call to wgrib to extract all the locations in the GRIB file for a given type and time. The original extract() method was designed for extracting GRIB data for a single location. I'm working on a project now that will create animated surf whether charts for a large area of ocean. Getting the data is much faster using Geo::ReadGRIB .05. *How much faster?* I posted some informal benchmarks [earlier http://pwizardry.com/devlog/index.cgi/2006/06/04#DBM.and.ReadGRIB] . Here are some results using a similar test using a different data set and a larger number of points. extract() no hits: 0.14/s 2.44s/ extractLaLo() no hits: 4.74/s .21s/ This just runs an extract for about 22000 data points using each method. The "no hits" means the objects were fresh and all data had to come from the GRIB file. (Recall, ReadGRIB will cache data in memory and only go to the file if it needs to.) It took the version using extract() about 2.4 seconds per run while extractLaLo() took just .21. That's over 11 times faster. Of course poor extract() was designed for single point at a time extraction but everyone loves a winner. For me, it means the difference between a starch and a coffee break while running tests that need a lot of new GRIB data. [/items/Perl] permanent link