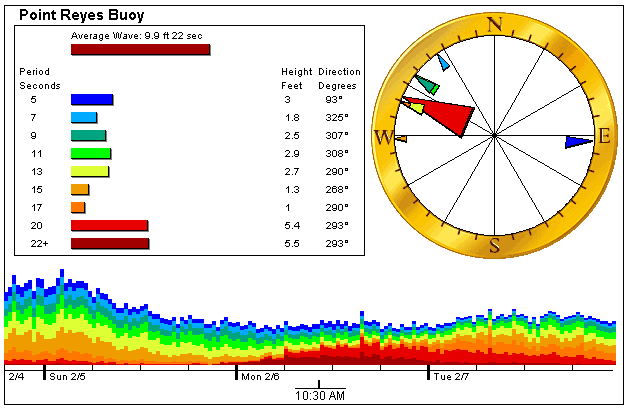
I added a logo to my buoy data images
While watching the POE demo app tail my web log files I noticed a referrer to a [certain http://www.niceness.org/new_surf/archives/001116.html] surfer's web site popped up a lot.
What was happening is that there is an <img> tag posted on the page pointing to one of my buoy data gifs.
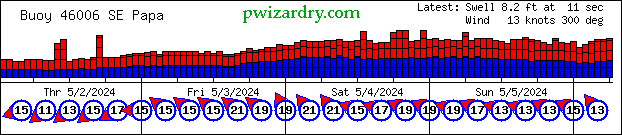 This image changes every hour so it makes a kind of sense to do it this way. The latest version will always display on his page. As an added bonus for the linker, it's my server that provides the resource.
Now Ethan is a really nice guy and I think it's great that the images are getting used by more local surfers. I did decide that I wanted to tag the images in some way though.
I added this text to all my buoy data images.:
This image changes every hour so it makes a kind of sense to do it this way. The latest version will always display on his page. As an added bonus for the linker, it's my server that provides the resource.
Now Ethan is a really nice guy and I think it's great that the images are getting used by more local surfers. I did decide that I wanted to tag the images in some way though.
I added this text to all my buoy data images.:
 It's pretty jaggy edged but that's because it has to be a GIF image. Anti aliasing would look strange too (especially on a non-white background like Ethan's site ;-).
I want to redo the images again to make this a little less prominent. I'm thinking of adding some extra space at the bottom for a line of text including a tag of some sort.
Coming soon...
It's pretty jaggy edged but that's because it has to be a GIF image. Anti aliasing would look strange too (especially on a non-white background like Ethan's site ;-).
I want to redo the images again to make this a little less prominent. I'm thinking of adding some extra space at the bottom for a line of text including a tag of some sort.
Coming soon...
[/items/Devlog]
permanent link
Fri, 03 Feb 2006
Perl Play: put on POE today
I installed POE and its /many/ dependencies tonight in ~/local/lib/site_perl and tested with a demo application from [Watching log files http://www.stonehenge.com/merlyn/PerlJournal/col01.html]
The application /tails/ the web server access log and displays the results on a web page colorized by time. It's a way to spot clusters of hits. Really though it's an interesting demo more than anything.
I hangs and dies after a while with the error:
[= Error accept Too many open files (24) happened after Cleanup!]
Cool so far...
[/items/Perl]
permanent link
Sat, 28 Jan 2006
Fix to coffeeFind Perl backend code
The new sort feature reveled an issue with the database data. Some of the fields have white space at the beginning. These were sorted to the top of the list. This is technically correct but not what I want to see.
I made a small change to the Perl code that scrapes the HTML coffee review files and puts the data into the database tables used by coffeeFind. Now I make sure there's no leading white space.
Fixed.
[/items/Rails]
permanent link
Fri, 27 Jan 2006
Late Night Rails Hacking
I finally circled back around and started poking at my CoffeeFind /*Ruby on Rails*/ application again. I stayed up way late. I wanted to get the [sort-by-column http://pwizardry.com/devlog/index.cgi/2006/01/06#CoffeeFind_I_Want] feature working and I couldn't quit in the middle.
*Lessons learned:*
just a random list so I don't forget...
- You have to start WEBrick from inside the application directory, /seems that way anyway.../
- To pass params from view to controller. In the view I do this:
/<% link_to "![sort]", :action => "show_ordered_by", :id => by %>/
The param here is "by" which is set up above:
/<% by = column.name %>/
I needed to do this because no matter what I did with quotes I couldn't just put /column.name/ as the :id value. This bit of code is used in a loop to put a sort tag on each of the column head cells so I can signal the controller method to sort on that column.
On the controller I have:
/def show_ordered_by/
/@reviews = Reviews.find(:all, :order => @params['id'])/
/end/
The @params array has the /id/ value the link will pass.
I had added the /*show_ordered_by*/ method to be the target of the links that will resort the table. I needed a separate view .rhtml file to display it. This file turned out to be identical to the one for the /*sort*/ method that draws the table the first time you view the link. In accordance with the DRY principle I changed the /*sort*/ method to be:
/redirect_to :action => 'show_ordered_by', :id => 'id'/
And for good measure I added a /*index*/ method which is identical. This way you just need to use [http://pwizardry.com/review http://pwizardry.com/review]
All this is based on approximately zero knowledge of Ruby or Rails so it's probably wack.
[/items/Rails]
permanent link
Sat, 14 Jan 2006
My new tableless, XHTML/CSS Devlog upgrade
I spent a lot of time this last week redesigning this devlog.
[/items/Devlog]
permanent link
Powered by Blosxom.
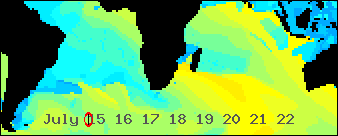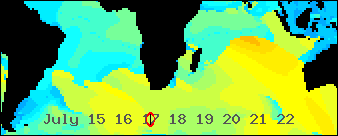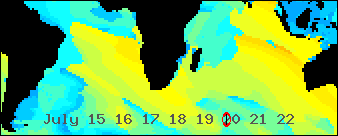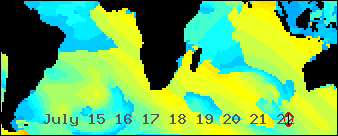 /An animated GIF abstracted from a world wide Wavewatch III GRIB dataset/
/showing all the seas were swells bound for southern Africa might be generated/
/An animated GIF abstracted from a world wide Wavewatch III GRIB dataset/
/showing all the seas were swells bound for southern Africa might be generated/
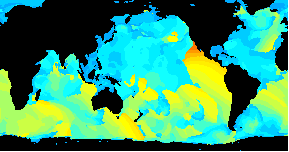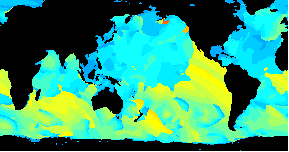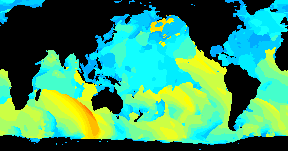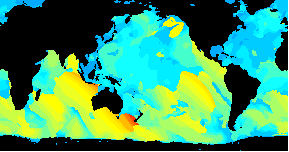 /An animated GIF of a world wide Wavewatch III GRIB dataset/
/An animated GIF of a world wide Wavewatch III GRIB dataset/
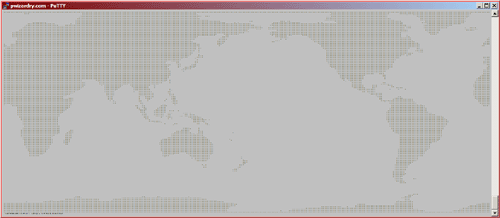 /This is a screen shot of my ssh session (set to 2-point type) printing data extracted using/
/Geo::ReadGRIB from a worldwide data set in a GRIB file. Since it's marine data, locations over/
/land are UNDEF and I print '*'. For anything else I print a space. This code was originally/
/developed to test my data extraction methods. Common errors like one-off would give a/
/distorted map. I adapted this code for my performance tests./
/This is a screen shot of my ssh session (set to 2-point type) printing data extracted using/
/Geo::ReadGRIB from a worldwide data set in a GRIB file. Since it's marine data, locations over/
/land are UNDEF and I print '*'. For anything else I print a space. This code was originally/
/developed to test my data extraction methods. Common errors like one-off would give a/
/distorted map. I adapted this code for my performance tests./